|
I am currently a Research Fellow at Harvard University, working closely with Marinka Zitnik at Harvard and Manolis Kellis at MIT. I received my PhD from Northeastern University, supervised by Prof. Yanzhi Wang. Prior to that, I earned my master degree from Northeastern University and B.E. degree from Huazhong University of Science and Technology (HUST), China. I was a research intern at Microsoft Research, ARM, and Samsung Research. I am a recipient of Machine Learning and Systems Rising Stars 2024. I am actively looking for faculty and industry positions starting Fall 2026. Please kindly reach out to me for any opportunities. Thanks! |

|
|
My research focuses on developing efficient and reliable AI systems for real-world generalization.
|
|
|
|
|
|


|
Selected Publications
* means equal contribution
|
|
|
Preprints
|
|

|
Zhenglun Kong*, Yize Li*, Fanhu Zeng, Lei Xin, Shvat Messica, Xue Lin, Pu Zhao, Manolis Kellis, Hao Tang, Marinka Zitnik PDF / Code We argue that viewing token reduction purely from an efficiency perspective is fundamentally limited. Instead, we position token reduction as a core design principle in generative modeling. |
|
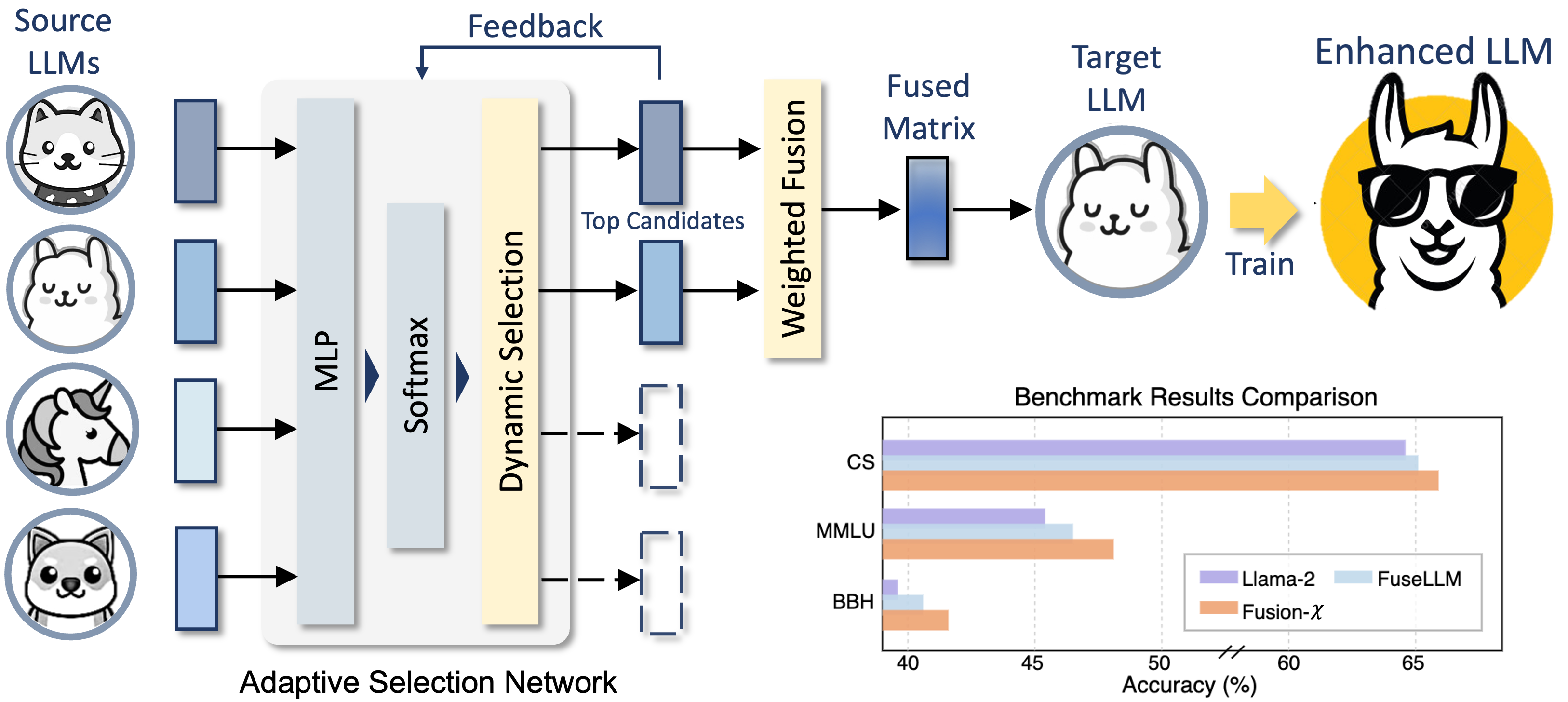
Zhenglun Kong*, Zheng Zhan*, Shiyue Hou, Yifan Gong, Xin Meng, Pengwei Sui, Peiyan Dong, Xuan Shen, Zifeng Wang, Pu Zhao, Hao Tang, Stratis Ioannidis, Yanzhi Wang PDF / Code We propose a framework that adaptively selects and aggregates knowledge from diverse LLMs to build a single, stronger model, avoiding the high memory overhead of ensemble and inflexible weight merging. |
|
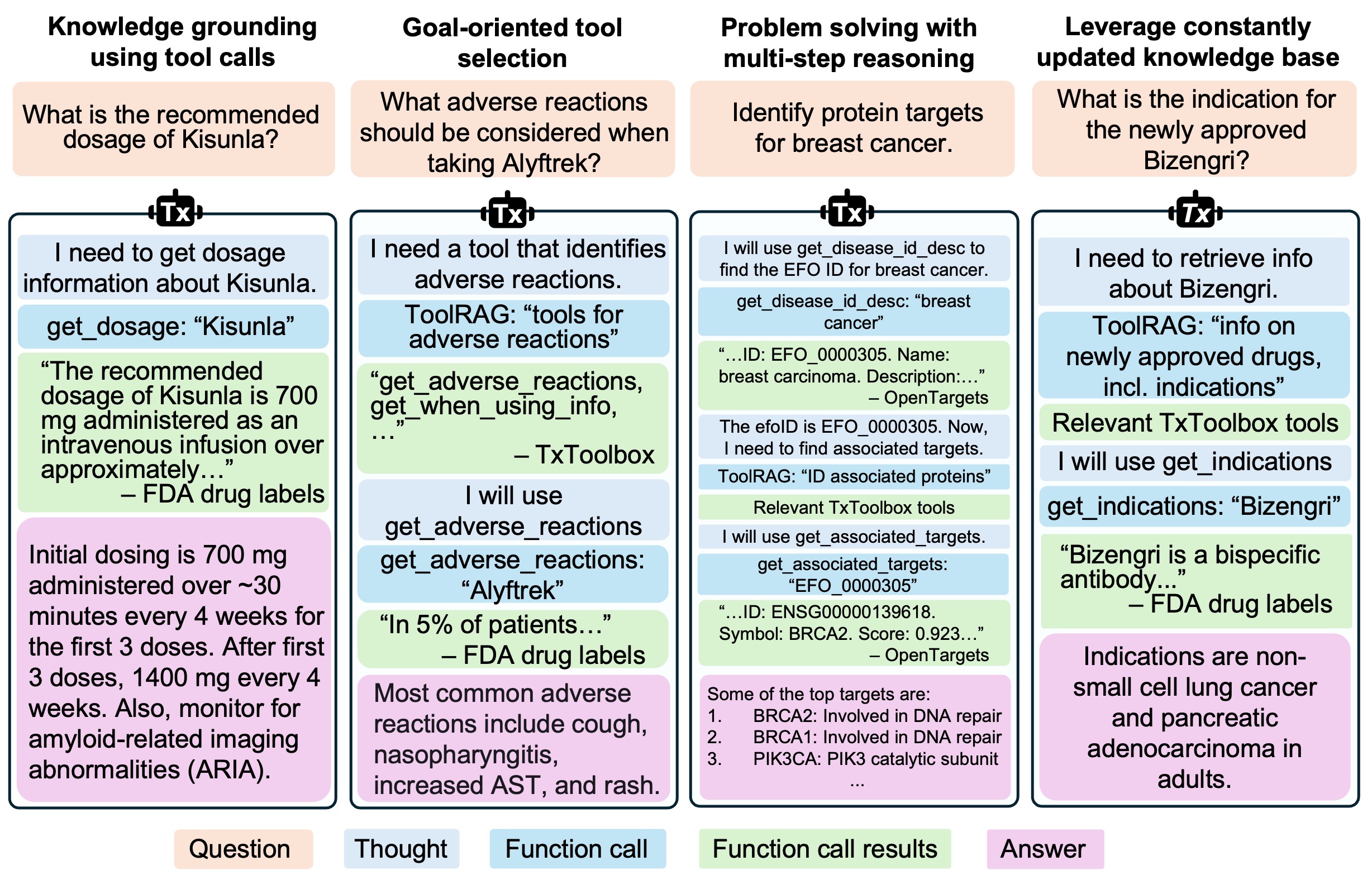
Shanghua Gao, Richard Zhu, Zhenglun Kong, Ayush Noori, Xiaorui Su, Curtis Ginder, Theodoros Tsiligkaridis, Marinka Zitnik PDF / Code We introduce TxAgent, an AI agent that leverages multi-step reasoning and real-time biomedical knowledge retrieval across a toolbox of 211 tools to analyze drug interactions, contraindications, and patient-specific treatment strategies. |
|
Published
|
|
|
Zhenglun Kong*, Mufan Qiu*, John Boesen, Xiang Lin, Sukwon Yun, Tianlong Chen, Manolis Kellis, Marinka Zitnik [ICML 2026] International Conference on Machine Learning We introduce SPATIA, a multi-scale generative and predictive model for spatial transcriptomics. SPATIA learns cell-level embeddings by fusing image-derived morphological tokens and transcriptomic vector tokens and then aggregates them at niche and tissue levels to capture spatial dependencies. |
|
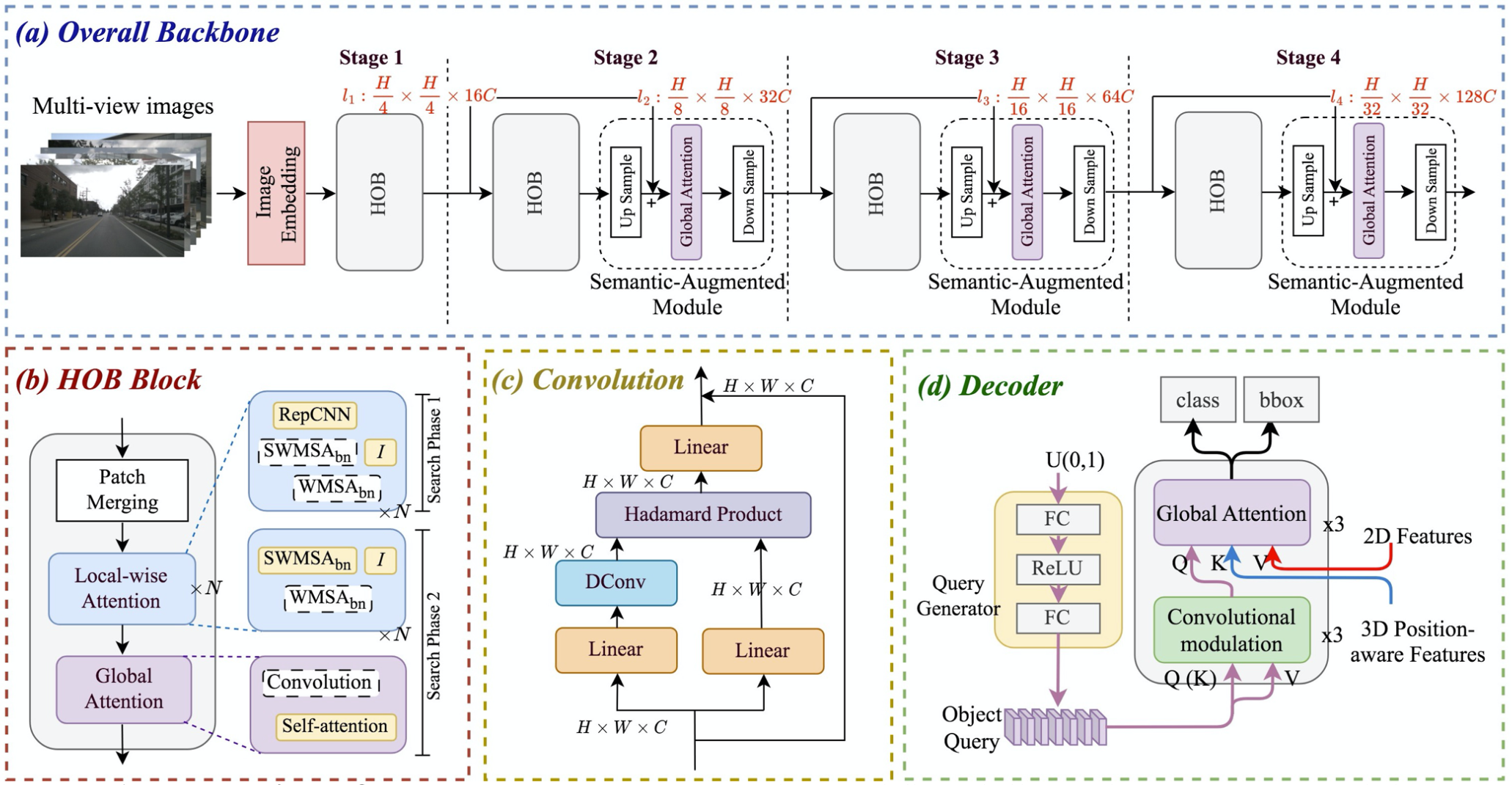
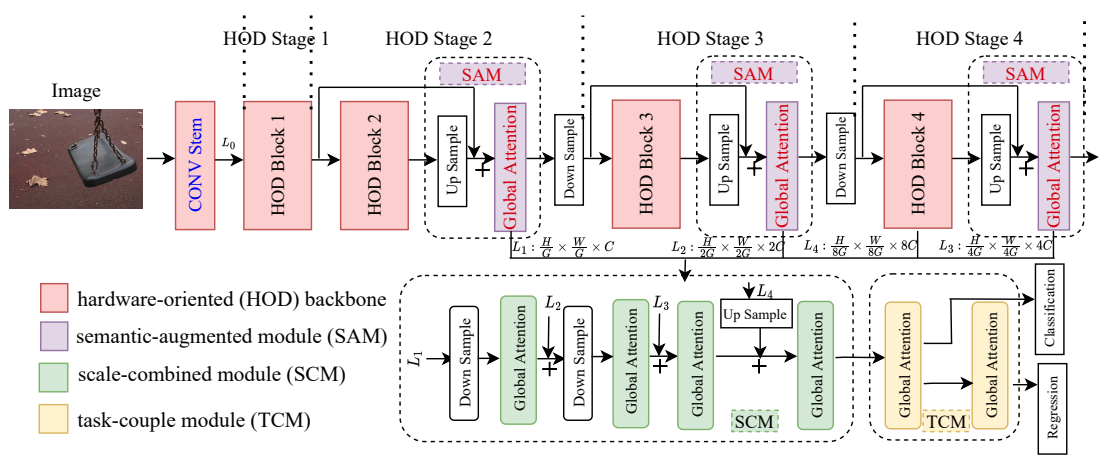
Zhenglun Kong, Dongkuan Xu, Zhengang Li, Peiyan Dong, Hao Tang, Yanzhi Wang, Subhabrata Mukherjee [IJCV] International Journal of Computer Vision We introduce a truly efficient, hardware-oriented approach for searching efficient vision transformer structure. This approach has been optimized to seamlessly adapt to the constraints of the target hardware and fulfill the specific speed requirements. |
|
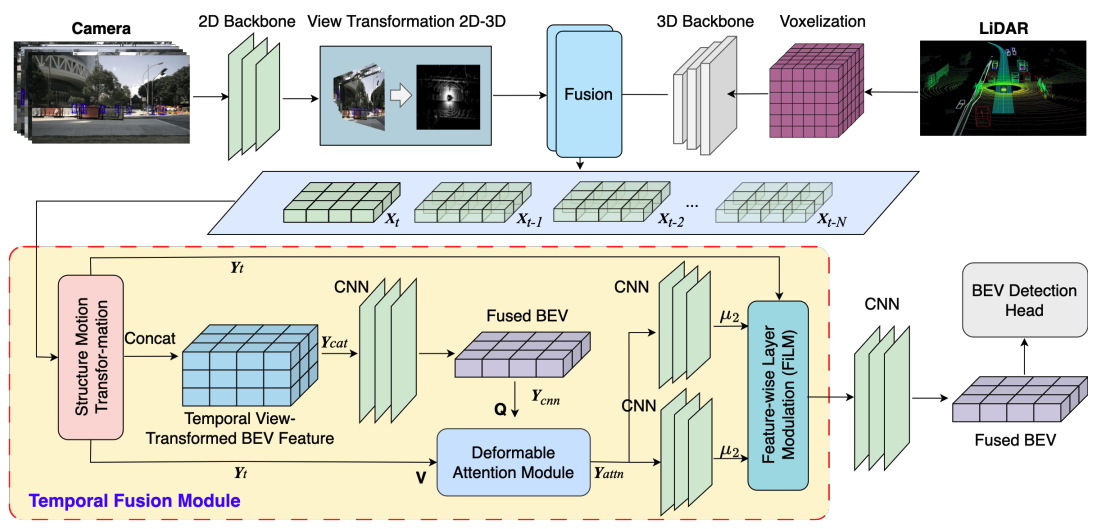
Pinrui Yu*, Zhenglun Kong*, Pu Zhao, Peiyan Dong, Hao Tang, Fei Sun, Xue Lin, Yanzhi Wang [WACV 2025] Winter Conference on Applications of Computer Vision We propose Q-TempFusion, a novel approach for temporal multi-sensor fusion designed to enhance the BEV model’s inference speed while keeping high predictive performance. |
|
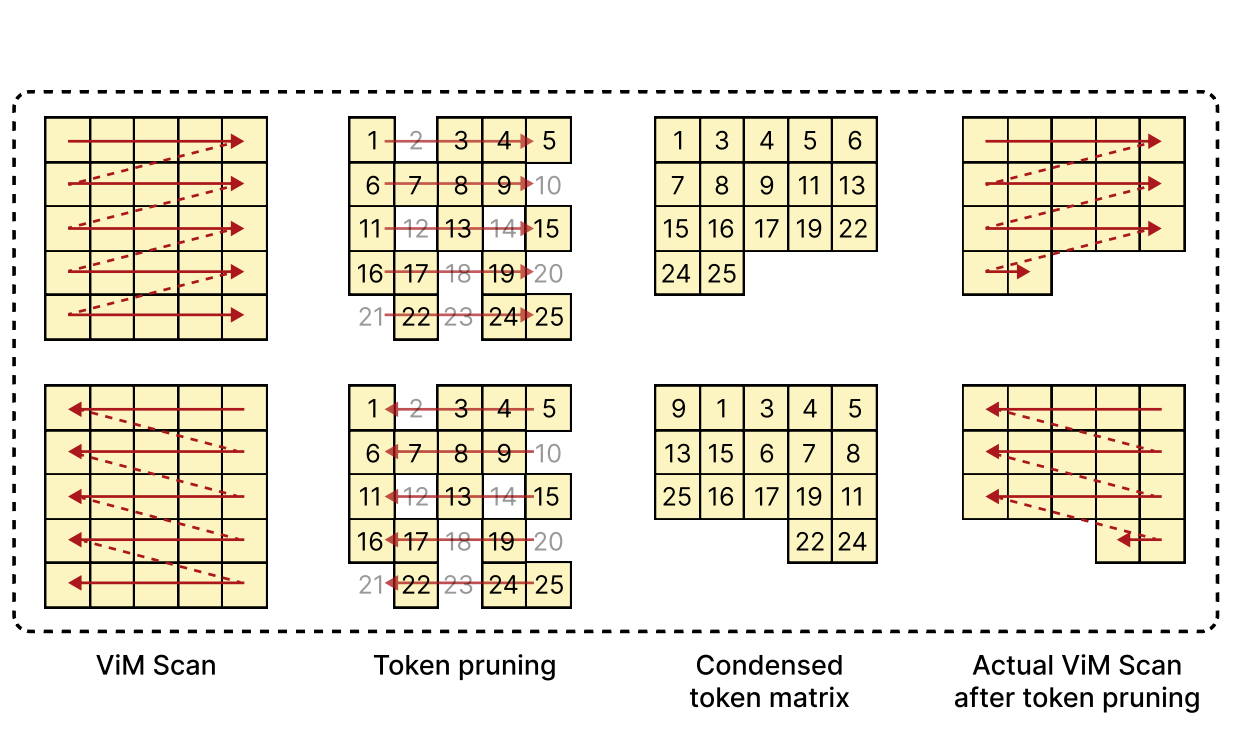
Zheng Zhan*, Zhenglun Kong*, Yifan Gong, Yushu Wu, Zichong Meng, Hangyu Zheng, Xuan Shen, Stratis Ioannidis, Wei Niu, Pu Zhao, Yanzhi Wang [NeurIPS 2024] Advances in Neural Information Processing Systems PDF / Code We revisit the unique computational characteristics of SSMs and discover that naive application disrupts the sequential token positions. This insight motivates us to design a novel and general token pruning method specifically for SSM-based vision models. |
|
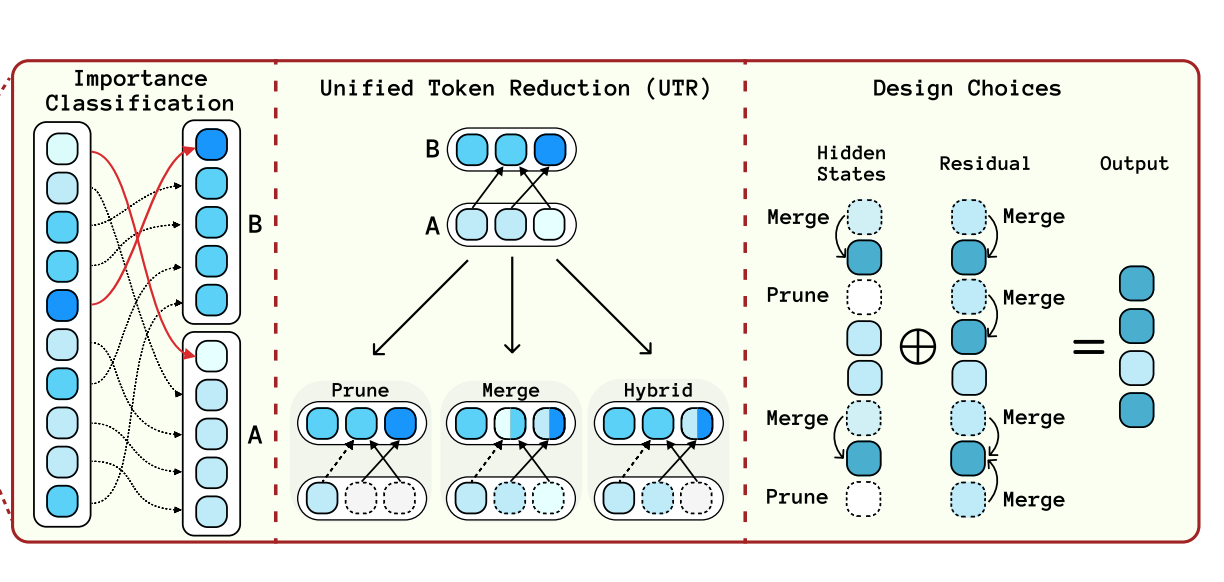
Zheng Zhan*, Yushu Wu*, Zhenglun Kong*, Changdi Yang, Yifan Gong, Xuan Shen, Xue Lin, Pu Zhao, Yanzhi Wang [EMNLP 2024] Conference on Empirical Methods in Natural Language Processing PDF / Code We propose a tailored, unified post-training token reduction method for SSMs. Our approach integrates token importance and similarity, thus taking advantage of both pruning and merging, to devise a fine-grained intra-layer token reduction strategy. |
|
Zhenglun Kong*, Peiyan Dong*, Xin Meng, Pinrui Yu, Yanyue Xie, Yifan Gong, Geng Yuan, Fei Sun, Hao Tang, Yanzhi Wang [NeurIPS 2023] Advances in Neural Information Processing Systems PDF / Code We present a hardware-oriented transformer-based framework for 3D detection tasks, which achieves higher detection precision and remarkable speedup across high-end and low-end GPUs. |
|
Peiyan Dong*, Zhenglun Kong*, Xin Meng, Peng Zhang, Hao Tang, Yanzhi Wang, Chih-Hsien Chou [ICML 2023] International Conference on Machine Learning PDF / Code We propose a novel speed-aware transformer for end-to-end object detectors, achieving high-speed inference on multiple devices. |
|
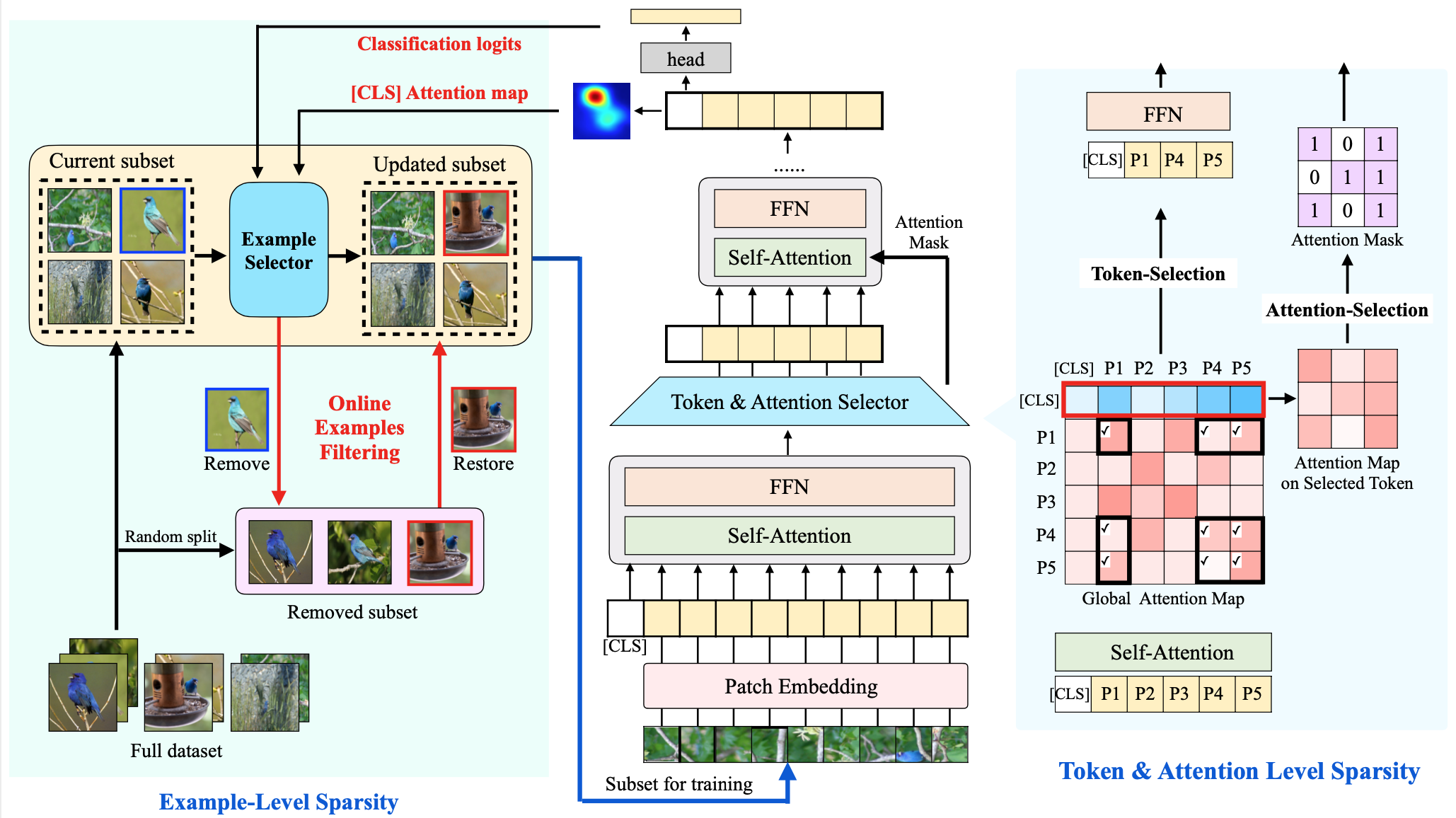
Zhenglun Kong, Haoyu Ma, Geng Yuan, Mengshu Sun, Yanyue Xie, Peiyan Dong, Yanzhi Wang, et al. [AAAI 2023 Oral] The Thirty-Seventh AAAI Conference on Artificial Intelligence PDF / Code We introduce sparsity into data and propose an end-to-end efficient training framework to accelerate ViT training and inference. |
|
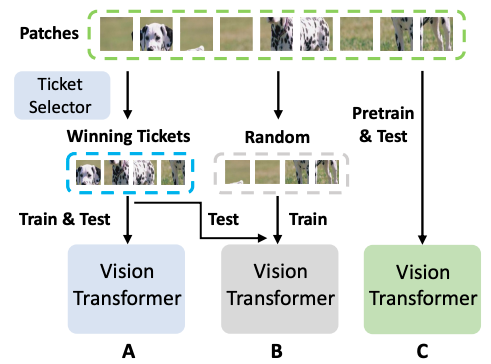
Xuan Shen, Zhenglun Kong, Minghai Qin, Peiyan Dong, Geng Yuan, Xin Meng, Hao Tang, Xiaolong Ma, Yanzhi Wang [IJCAI 2023 Oral] The 32nd International Joint Conference on Artificial Intelligence PDF / Code We generalize the LTH for ViTs to input data consisting of image patches inspired by the input dependence of ViTs. That is, there exists a subset of input image patches such that a ViT can be trained from scratch by using only this subset of patches and achieve similar accuracy to the ViTs trained by using all image patches. |
|
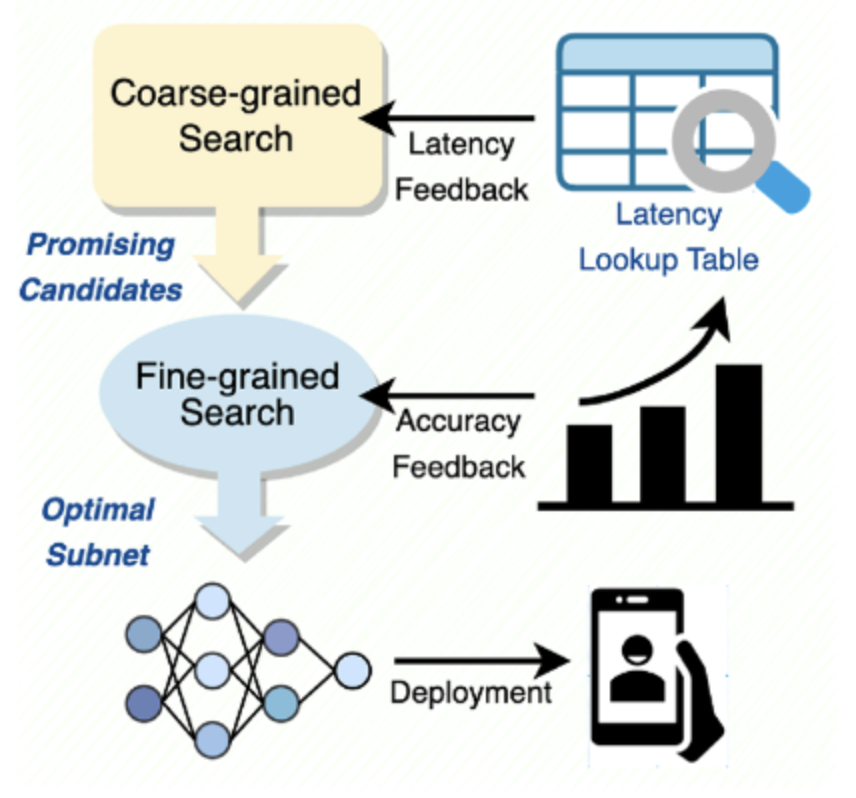
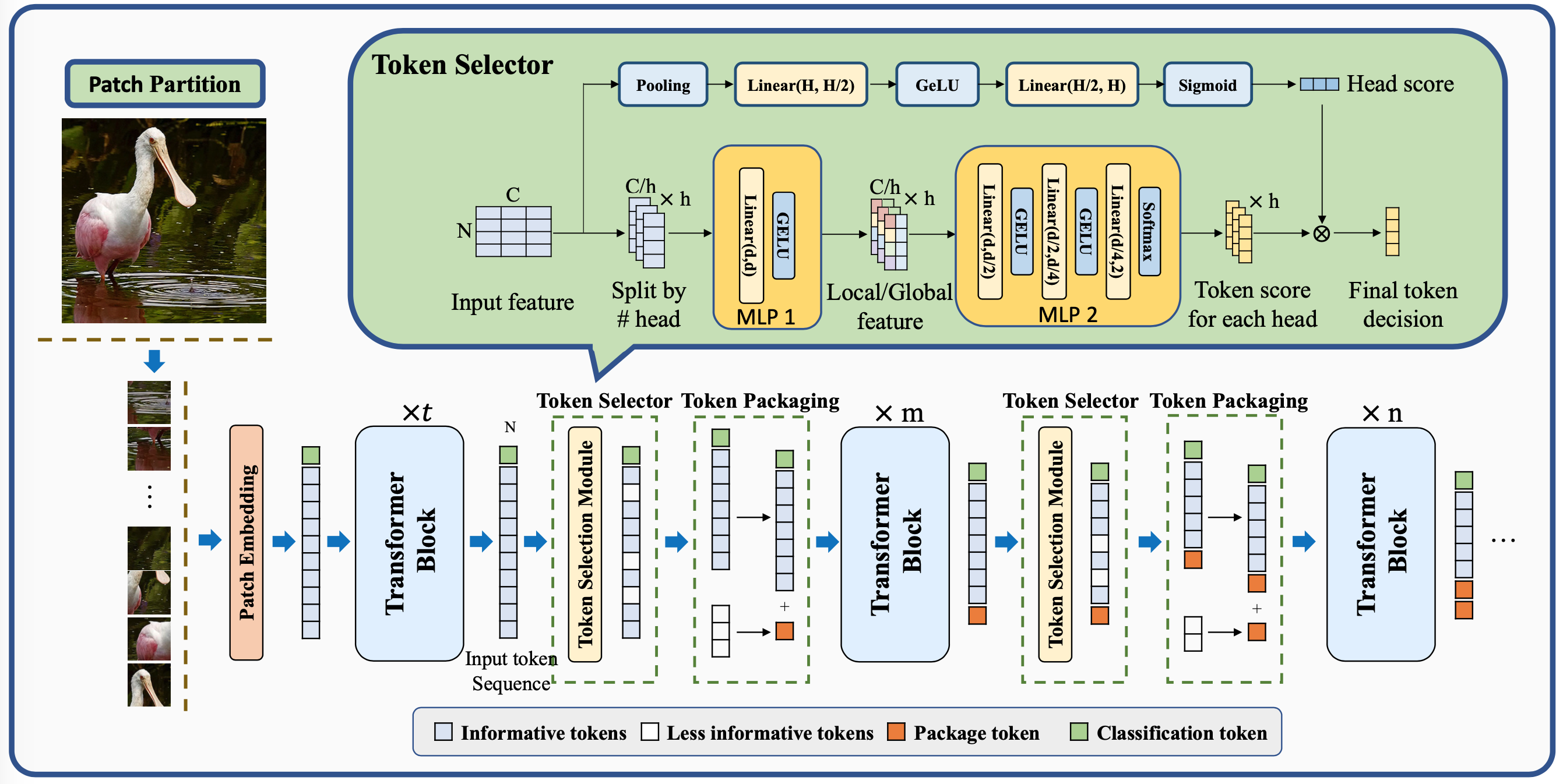
Zhenglun Kong, Peiyan Dong, Xiaolong Ma, Xin Meng, Mengshu Sun, Wei Niu, Xuan Shen, Geng Yuan, Bin Ren, Minghai Qin, Hao Tang, Yanzhi Wang [ECCV 2022] European Conference on Computer Vision CVPRW 2022 Spotlight PDF / Code We propose a dynamic, latency-aware soft token pruning framework for Vision Transformer. Our framework significantly reduces the computation cost of ViTs while maintaining comparable performance on image classification. |
|
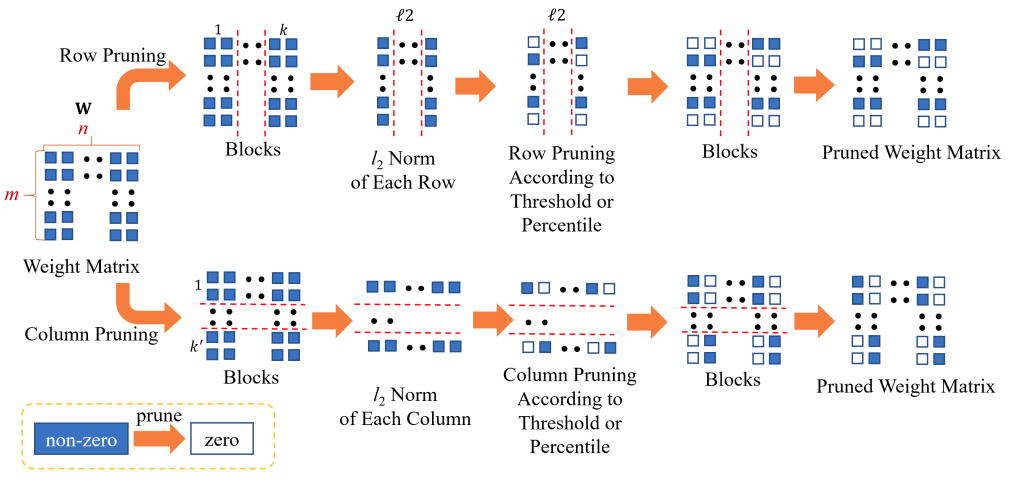
Bingbing Li*, Zhenglun Kong*, Tianyun Zhang, Ji Li, Zhengang Li, Hang Liu, Caiwen Ding [EMNLP 2020 Findings] Conference on Empirical Methods in Natural Language Processing PDF / Code We propose an efficient transformer-based large-scale language representation using hardware-friendly block structure pruning. We incorporate the reweighted group Lasso into block-structured pruning for optimization. |
|
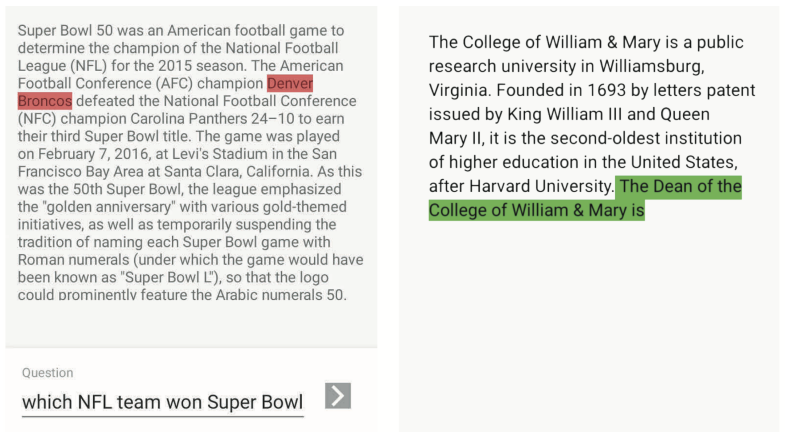
Wei Niu*, Zhenglun Kong*, Geng Yuan, Weiwen Jiang, Jiexiong Guan, Caiwen Ding, Pu Zhao, Sijia Liu, Bin Ren, Yanzhi Wang [IJCAI 2021 Demo] 30th International Joint Conference on Artificial Intelligence We propose a compression-compilation codesign framework that can guarantee BERT model to meet both resource and real-time specifications of mobile devices. |
|
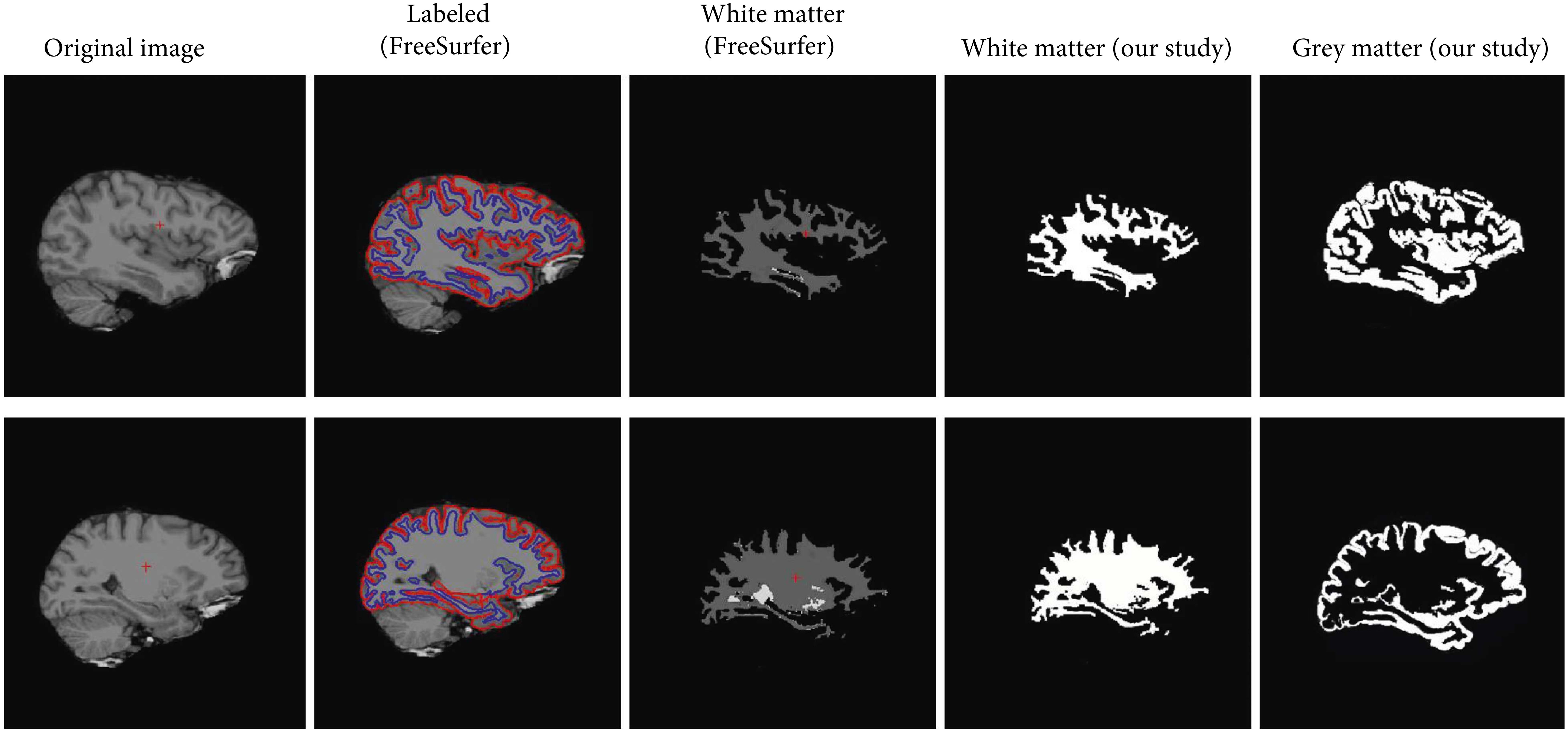
Zhenglun Kong, Ting Li, Junyi Luo, Shengpu Xu Journal of Healthcare Engineering We realize automatic image segmentation with convolutional neural network to extract the accurate contours of four tissues: the skull, cerebrospinal fluid (CSF), grey matter (GM), and white matter (WM) on 5 MRI head image datasets. |
|
|

|
|
|